Mejora del modelado de plantas con aprendizaje automático
La integración del aprendizaje automático y el modelado de cultivos puede optimizar las predicciones sobre el crecimiento y el rendimiento de los cultivos.
A medida que empeora el cambio climático, los científicos están trabajando para encontrar los métodos, algoritmos o modelos más potentes para simular los efectos de las altas temperaturas y/o la disponibilidad limitada de agua en el crecimiento, desarrollo y productividad de las plantas. La complejidad de las interacciones planta-entorno complica esto, pero una nueva investigación ha demostrado que la integración del aprendizaje automático y el modelado de plantas puede proporcionar las respuestas necesarias.
dr. Ioannis Droutsas, investigador de la Universidad de Leeds, y los coautores han integrado algoritmos de aprendizaje automático (ML) en un modelo de cultivo basado en procesos para crear un nuevo marco de modelado de cultivos/ML con alto rendimiento en la representación de la respuesta del cultivo a una amplia gama para crear una variedad de entornos, incluidas condiciones estresantes.
Los autores modificaron el modelo de cultivo existente basado en procesos GLAM-Parti incorporando algoritmos de aprendizaje automático para estimar variables que normalmente eluden la capacidad predictiva del modelo de cultivo. . ML se utilizó para las predicciones diarias de la eficiencia del uso de la radiación, la tasa de cambio del índice de cultivo y la etapa fenológica.
Para la evaluación del nuevo marco GLAM-Parti-ML, los autores utilizaron un conjunto de datos existente para una variedad de trigo cultivada en un amplio rango de temperatura, radiación solar y humedad, incluido el estrés por calor. La mitad de los datos se utilizó para entrenar los algoritmos de aprendizaje automático y la otra mitad para probar el modelo.
El modelo se ejecutó con los datos meteorológicos de temperatura, radiación solar y déficit de presión de vapor, los determinantes climáticos clave del crecimiento del trigo en condiciones de riego y buena fertilización. Los resultados de rendimiento de biomasa y grano, así como los días de floración y madurez, se compararon con las mediciones de campo al final de la temporada.

El equipo aplicó Random Forests y Extreme Gradient Boost. Ambos modelos ML mostraron una alta eficiencia en el aprendizaje de los patrones entre los insumos y el rendimiento de la planta (en términos de eficiencia en el uso de la radiación) durante la temporada de crecimiento. Esto dio como resultado una buena capacidad de modelado para la biomasa vegetal; GLAM-Parti-ML reprodujo el 98 % de la varianza observada tanto en biomasa como en rendimiento de grano, y el error del modelo fue inferior al 20 %. Además, el modelo reprodujo al menos el 98 % de la variación observada en días hasta la floración y madurez con menos del 11 % de error. Sin embargo, se subestimó el inicio de ambas etapas fenológicas, prediciendo la antesis y la madurez antes de lo observado.

A continuación, GLAM-Parti se comparó con su predecesor GLAM, un modelo de recolección basado en procesos sin integración de aprendizaje automático. GLAM se calibró con el 100% de los datos y GLAM parti con solo el 50%. Aún así, GLAM-Parti-ML tuvo valores de error más bajos para biomasa, rendimiento y días hasta la madurez y antesis, lo que indica que las parametrizaciones de aprendizaje automático mejoraron el modelo a pesar de que solo se entrenó con la mitad de los datos.
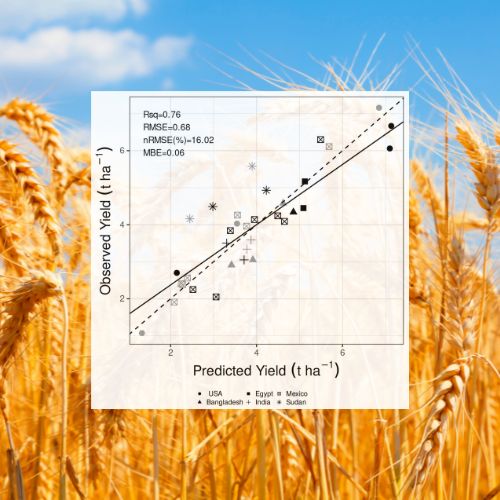
Para evaluar más a fondo GLAM-Parti-ML, los autores utilizaron un segundo conjunto de datos de tres variedades de trigo cultivadas en muchos ensayos de campo en seis países. Nuevamente, la mitad de los datos se usaron para entrenar los algoritmos de aprendizaje automático y la otra mitad para probar el modelo.

Una vez más el modelo mostró un excelente desempeño. Reprodujo el 73% de la variación de biomasa entre sitios y variedades con 15% de error y el 76% de la variación de rendimiento de grano con 16% de error. La fenología de la planta fue más precisa para los días hasta la madurez (9,9 % de error) que para la antesis (13,2 % de error). Nuevamente, hubo un sesgo negativo en la predicción de ambas etapas fenológicas.
Droutsas concluye: “Usar un conjunto de datos de entrenamiento más grande mejoraría significativamente las simulaciones del modelo. Sin embargo, solo hay unos pocos conjuntos de datos con las medidas requeridas”.
LEER EL ARTÍCULO:
Ioannis Droutsas, Andrew J Challinor, Chetan R Deva, Enli Wang, Integración del aprendizaje automático en el modelado basado en procesos para mejorar la simulación de respuestas complejas de cultivos, in silico Plants, 2022, diac017, https://doi.org/10.1093/insilicoplants /diac017